
Sekundenschnelle Berichte trotz Millionen von Daten aus einer Vielzahl unterschiedlicher Kanäle. Wir erklären, wie es geht.
Mit zunehmender Komplexität geht Google Looker Studio in die Knie und bedankt sich mit sehr langen Ladezeiten. Ein Multichannel Reporting umfasst bei uns schnell mal 110 Diagramme und 48 Filter auf 13 Seiten.
Im nachfolgenden Artikel wird erklärt, wie man durch die Aufbereitung der Daten in BigQuery die Geschwindigkeit und damit die Bedienungsfreundlichkeit von Looker Studio Reports erheblich steigern kann.
— innerhalb weniger Sekunden —
Denn die lange Ladezeit liegt an der Aggregation und Verarbeitung der Daten von Google Looker Studio. Wenn die Daten vorher in BigQuery aufbereitet werden, laden auch Looker Studio Reports mit mehreren hunderttausend Produkten und Millionen Datenpunkten innerhalb weniger Sekunden.
Wie sieht eine optimierte Datenquelle für Looker Studio aus?
Ziel ist es, eine einzige, möglichst flache Datenquelle zu generieren. Aus dieser kann Looker Studio die Daten für die Diagramme und Filter ziehen, ohne diese vorher mit weiteren Datenquellen verknüpfen zu müssen oder komplizierte Berechnungen in benutzerdefinierten Feldern innerhalb der Datenquelle durchführen zu müssen. Stellen Sie deshalb zunächst zusammen, welche Messwerte dargestellt werden sollen und nach welchen Dimensionen Sie diese filtern oder segmentieren möchten.
Für unser Beispiel benötigen wir folgende Datenfelder:
- Messwerte: Besuche, Bestellungen, Neukunden, Umsatz, Kosten
- Berechnete Felder: Konversionsrate, Kosten/Umsatz-Relation, Neukundenquote
- Dimensionen: Datum, Kanal, Unterkanal
Um später bei der Wahl der Auswertungszeiträume und etwaiger Vergleichszeiträume, sowie bei der segmentierten Darstellung – zum Beispiel nach Wochen – möglichst flexibel zu sein, benötigen Sie die Daten auf Tagesbasis.
So könnte die Kopfzeile der benötigten Datenquelle aussehen:

Woher kommen die Daten für das Reporting?
Besuche, Bestellungen, Neukunden und Umsatz je Datum, Kanal und Unterkanal erhalten Sie idealerweise aus Ihrem Webanalysetool. Mit Tools wie Supermetrics lassen sich die Daten automatisiert abrufen und zum Beispiel in einem Google Sheet oder direkt in BigQuery speichern.
Die Kostendaten stammen üblicherweise direkt von den Plattformen, in unserem Beispiel aggregieren wir diese von Google, Bing, Meta und drei Preisvergleichsportalen. Auch die Daten der ersten drei Anbieter können Sie über Tools sehr einfach in der benötigten Form abrufen. Bei den Preisvergleichern müssen Sie aber vermutlich improvisieren:
— Automatisieren mit Scripts —
Nehmen wir an, der erste Preisvergleicher schickt die Daten als Anlage per E-Mail, der zweite lädt sie via FTP auf Ihren Server hoch und der dritte bietet einen Datenabruf mittels API an. Spätestens an dieser Stelle würden einige vermutlich zur manuellen Übertragung wechseln und die relevanten Daten aus den Reports der Preisvergleicher in ein Google Sheet importieren. Wir automatisieren das in unserem Beispiel mit einem kleinen Bash Script und zwei kleinen Google Scripts.
Wie kommen die Daten in Form?
Die zusammengestellten Kostendaten müssen später anhand von Datum, Kanal und Unterkanal der jeweiligen Datenzeile aus dem Webanalysetool zugeordnet werden. Dabei hilft eine schematische Benennung aller Kampagnen und/oder ein durchgängiges Tracking mit URL-Parametern.
In unserem Beispiel verwenden wir vom Kunden definierte Kampagnen-Codes, die in allen Kampagnen als URL-Parameter angehängt werden. Mithilfe der Kampagnen-Codes und einer Matching-Tabelle können wir sowohl Kostendaten als auch die Daten aus der Webanalyse eindeutig einem Unterkanal zuordnen.
Als Zwischenstufe können Sie sich folgende Rohdatenquellen vorstellen:
Daten aus der Webanalyse:

Kostendaten je Plattform:

Matching-Tabelle für Kampagnen-Codes:

Liegen alle Daten in dieser Form vor, ist es mit BigQuery relativ einfach, diese zu einer flachen Datenquelle für Looker Studio zu kombinieren. Aber eins nach dem anderen…
Vorbereitung (optional)
Für die weiteren Schritte ist es hilfreich, wenn Sie sich bereits mit Ihrem Google Konto in der Google Cloud angemeldet und dort in BigQuery ein Projekt mit einem Dataset eingerichtet haben.
Einen Einstieg in die Funktionsweise von Abfragen in BigQuery erhalten Sie hier: Overview of BigQuery analytics | Google Cloud. Wenn Sie noch eine Stufe früher einsteigen möchten, beginnen Sie am Besten hier: Enable the BigQuery sandbox | Google Cloud.
Abrufen und Importieren der Daten in BigQuery
Wir nutzen in unserem Beispiel das Tool Supermetrics for Google Sheets und speichern die abgerufenen Daten in einem Google Sheet, das wir anschließend als externe Tabelle in BigQuery importieren. Dazu erstellen wir in unserem Dataset eine neue Tabelle aus “Drive” im Dateiformat “Google-Tabelle” unter Angabe der URL des Google Sheets.

Als Ziel des Imports definieren wir in unserem bestehenden Dataset eine neue Tabelle, der wir einen sprechenden Namen geben, zum Beispiel “import_webanalyse”:

Das Schema für die Tabelle, also die Feldnamen und jeweiligen Datentypen, definieren wir manuell mit sprechenden Bezeichnungen für die weitere Verwendung in SQL-Abfragen:
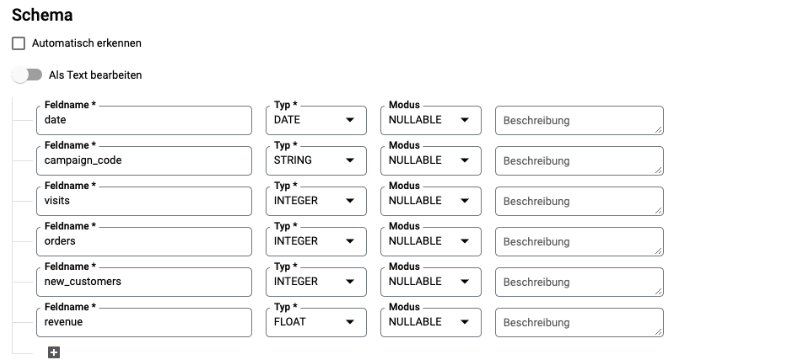
Sofern im Google Sheet eine Kopfzeile vorhanden ist, überspringen wir diese beim Import:

Mit Klick auf “Tabelle erstellen” ist das Google Sheet den Quelldaten mit BigQuery verknüpft. Diesen Vorgang wiederholen wir für alle zu importierenden Google Sheets.
— Sheets als temporäre Datenpools nutzen —
Werden Daten dieser Tabellen abgefragt, lädt BigQuery diese Daten aus dem jeweiligen Google Sheet, was bei großen Datenmengen zu Verzögerungen führen kann. Die Google Sheets können aber auch als temporäre Datenpools genutzt werden. Mittels regelmäßiger Abfragen können die jeweils neuen Daten aus den Google Sheets in eine eigens dafür erstellte, interne BigQuery Tabelle übertragen respektive angehängt werden.
Diese Methode funktioniert hervorragend für Daten, die automatisiert mit Tools abgerufen werden können oder in standardisierten Formaten vorliegen. Unsere Lösung für Sonderfälle haben wir am Beispiel der drei Preisvergleichsportale am Ende des Artikels angehängt.
Erstellung der Datenquelle für Looker Studio
Mit SQL können wir die vollständig importierten Daten nicht nur einfach zusammenfügen, sondern gegebenenfalls auch Berechnungen mit oder Modifikationen an den Daten vornehmen. Eine SQL-Abfrage zur Zusammenführung der Daten aus sechs Datenquellen und einer Matching-Tabelle kann sauber formatiert schon mal über 100 Zeilen lang sein.
— Werte vorab modellieren —
Wir verwenden für Abfragen uneinheitlicher Kostendaten WITH Statements, um Feldnamen aber auch manche Werte vorab zu modellieren, damit sie im nächsten Schritt über UNION ALL zu einer homogenen Datenquelle zusammengefasst und anschließend mit LEFT JOIN sauber zugeordnet werden können. Das ist insbesondere dann sehr hilfreich, wenn eine wichtige ID, wie in unserem Beispiel der Kampagnen-Code, nicht als separates Feld in der Datenquelle zur Verfügung steht, sondern aus einem anderen Textfeld extrahiert werden muss.
Das Ergebnis unserer Abfrage schreiben wir in eine neue Tabelle die wir später in Looker Studio als Quelle hinzufügen können. Die Option finden Sie im BigQuery Abfrageeditor unter “MEHR > Abfrageeinstellungen”:
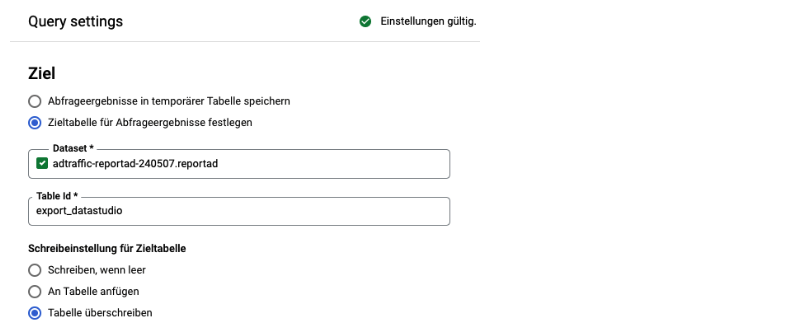
Die Datenquelle für Looker Studio können Sie aktuell halten, indem Sie eine leicht modifizierte Abfrage als geplanten Abfrage speichern, die täglich automatisiert die neuen Daten anhängt.
Hinzufügen der Datenquelle zu Looker Studio
Die fertig vorbereitete Datenquelle verknüpfen Sie aus Looker Studio heraus ganz einfach, indem Sie unter “Daten hinzufügen” den Connector für BigQuery anklicken und anschließend aus Ihrem Projekt und Dataset die neu erstellte Exporttabelle auswählen.
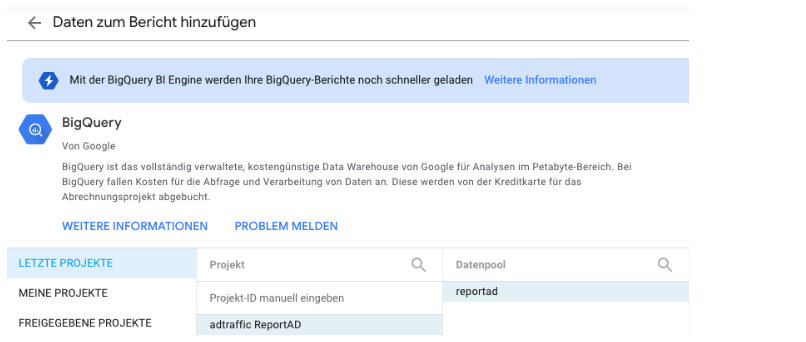
Ab hier können Sie nun wie gewohnt mit der Zusammenstellung Ihres Reports in Looker Studio loslegen. Mit dem großen Unterschied, dass Sie keine Tabellen mehr verknüpfen müssen und die einzelnen Seiten deutlich schneller geladen werden.
In unserem Beispiel haben wir drei berechnete Felder vorgesehen. Diese können Sie natürlich bereits in der SQL-Abfrage zur Erstellung der Exporttabelle ergänzen. Es ist aber auch möglich, innerhalb von Looker Studio einer BigQuery Datenquelle berechnete Felder hinzuzufügen.
Viel Spaß und Erfolg beim Reporting Ihrer Kampagnen-Performance!
Darauf können Sie zählen
Wieviel die Optimierung von Datenquellen mit BigQuery für Looker Studio bringt, zeigt sich vor allem bei umfangreichen Reports.
Unser jüngstes Projekt besteht zum Beispiel aus:
- 123 Diagrammen
- auf 16 Seiten
- aus vier optimierten Datenquellen
- davon 12 Diagramme aus zwei separaten Datenquellen
- und eine zusätzliche Import-Statustabelle mit separater Datenquelle
110 Diagramme und 48 Filter auf 13 Seiten entspringen also nur einer einzelnen Datenquelle.
Im gesamten Reporting werden nur sechs berechnete Felder verwendet. Es wird keine einzige zusammengefügte Datenquelle benötigt.
Die Seiten dieses Reporting laden spürbar schneller als ein vergleichbares Reporting mit direkter Google Analytics und Google Ads Verknüpfung und sogar deutlich schneller als ein weiteres Kundenreporting mit einer Vielzahl direkter Google Analytics Verknüpfungen.
ANHANG
Sonderfälle auf Spur bringen
Manche Daten können nicht standardisiert über Tools abgerufen werden. In dem Fall gilt es, zwei Herausforderungen zu meistern: Zuerst sollen die Daten automatisiert empfangen und eingelesen werden. Anschließend sollen sie verarbeitet und in Form für den weiteren Import in BigQuery gebracht werden. Dabei kann erschwerend hinzukommen, dass die Daten mehrerer gleich zu behandelnder Quellen völlig unterschiedlich ankommen.
Um ein Beispiel zu nennen: Ein Preisvergleicher schickt per E-Mail die Kostendaten pro Tag inklusive der Anzahl an Impressionen und Klicks. Der zweite lädt eine Datei mit einer Zeile pro Klick via FTP auf unseren Server – ohne Kostendaten. Und der dritte stellt eine REST-API zur Verfügung, über die tagesgenau sowohl Kosten als auch Klicks abgefragt werden können, nicht aber die Impressionen.
Am Ende soll ein Google Sheet herauskommen, das folgende Kopfzeile haben könnte:

Um die Daten in dieser Form aufzubereiten und an das Sheet anzuhängen, nutzen wir Google Apps Scripts in zwei Ausführungen: Eine Variante liest die Daten aus den Anhängen der E-Mails, die über ein dediziertes Reporting-Postfach empfangen wurden. Die andere ruft die Daten über REST-APIs ab. Beiden folgt eine einheitliche Export-Funktion zur Übertragung der aufbereiteten Daten in das gemeinsame Google Sheet.
Das funktioniert deshalb so reibungslos, weil Google Apps Scripts sehr unkompliziert mit GMail und Google Sheets interagieren kann. Die via FTP empfangenen Daten senden wir deshalb mittels Bash-Script direkt vom FTP-Server ebenfalls an das Reporting-Postfach und führen sie so der automatisierten Weiterverarbeitung zu.
So kann das ordentlich formatierte Google Sheet auch einfach in BigQuery importiert werden (siehe Abrufen und Importieren der Daten in BigQuery).
Nachfolgend finden Sie einige Beispielcodes dazu.
In Google Sheet schreiben
Fertig aggregierte Daten lassen sich mittels Google Apps Script ganz einfach in ein Google Sheet schreiben.
function writeData(fileID,sheetName,output){
if (output.length === 0) { return; }
var sheet = SpreadsheetApp.openById(fileID).getSheetByName(sheetName);
var lastRow = sheet.getLastRow();
var lastColumn = sheet.getLastColumn();
sheet.getRange(lastRow + 1, 1, output.length, lastColumn).setValues(output);
}E-Mail-Anhänge auslesen
Die zu aggregierenden CSV-Daten lassen sich aus E-Mail-Anhängen ebenfalls sehr einfach mit Google Apps Script auslesen.
function iterateThreads(query){
var threads = GmailApp.search(query,0,3);
for(i=0;i<threads.length;i++){
var subject = threads[i].getFirstMessageSubject();
var messages = threads[i].getMessages();
var message = messages[messages.length-1];
var date = message.getDate();
var attachment = message.getAttachments({includeInlineImages:false})[0];
processAttachement(date,attachment); // verarbeitet den E-Mail-Anhang
GmailApp.moveThreadToArchive(threads[i]);
}
}
function processAttachement(date,attachment){
var separator = ";"
var csvData = Utilities.parseCsv(attachment.getDataAsString(), separator);
var impressions = 0;
var clicks = 0;
var cost = 0;
for (i=1;i<csvData.length-1;i++){
var line = csvData[i][0].split(",");
if (parseInt(line[2]) && parseInt(line[3]) && parseFloat(line[4])){
impressions += parseInt(line[2]);
clicks += parseInt(line[3]);
cost += parseFloat(line[4]);
}
}
prepareData(date,impressions,clicks,cost);
}Daten abgleichen und in Form bringen
Die ausgelesenen Daten lassen sich anschließend mit ein paar Codezeilen mit den bereits bestehenden Daten abgleichen und vor dem Schreiben in das Google Sheet in Form bringen.
function prepareData(date,impressions,clicks,cost){
if (checkIfExisting(date) === 0){
output.push([date,impressions,clicks,cost]); // schreibt in globale Variable
}
}
function checkIfExisting(date){
var values = readSheetValues(fileID,sheetName);
if (!values) { return 0; }
var filtered = values.filter(function(e){
if (e.indexOf(date) != -1){
return 1;
}
});
return filtered.length;
}
function readSheetValues(fileID,sheetName){
sheet = SpreadsheetApp.openById(fileID).getSheetByName(sheetName);
lastRow = sheet.getLastRow();
lastColumn = sheet.getLastColumn();
if (lastRow === 1) {
return;
}
return sheet.getRange(2,1,lastRow-1,lastColumn).getValues();
}Unterschiedlich formatierte Daten
Bei unterschiedlichen Formatierungen der eingehenden CSV-Daten kann man sich mit Prozessschleifen behelfen.
else if (comp === "ladenzeile") {
var date = fileName.match(/(\d{4}-\d{2}-\d{2})/)[1];
var clicks = 0;
var cost = 0;
for (i=1;i<csvData.length-1;i++){
var line = csvData[i];
clicks += 1;
cost += parseFloat(line[5]);
}
prepareData(date,comp,0,clicks,cost);
}Abruf über APIs
Auch über REST-APIs lassen sich mittels Google Apps Script relativ einfach Daten abrufen.
function idealoMain(){
Logger.log("Processing idealo");
const sysdate = new Date();
const offset = new Date().getTimezoneOffset();
const today = new Date(sysdate.getTime() - (offset*60*1000));
today.setDate( today.getDate() - 1 );
const querydate = today.toISOString().split("T")[0];
const shopId = "123456789";
const siteId = "IDEALO_DE";
const fromDate = querydate;
const toDate = querydate;
const cpc = 0.12;
const access_token = idealoGetAccessToken();
const idealoClickReport = idealoDownloadDailyClickReport(shopId,siteId,fromDate,toDate,access_token);
var dataLength = idealoClickReport.findIndex(function(el){ return el[0] === ""});
for(i=1;i<dataLength;i++){
var line = idealoClickReport[i][1].split(';')
var date = line[0].match(/(\d{4}-\d{2}-\d{2})/)[1]
var clicks = line[1];
var cost = line[1] * cpc;
prepareData(date,"idealo",0,clicks,cost)
}
}
function idealoGetAccessToken(){
const url = "https://businessapi.idealo.com/api/v1/oauth/token";
const response = UrlFetchApp.fetch(url, {
"method": "POST",
"headers": {
"Authorization": "Basic ************************************************",
"Content-Type": "application/javascript",
},
"muteHttpExceptions": true,
"followRedirects": true,
"validateHttpsCertificates": true,
"contentType": "application/javascript",
});
return JSON.parse(response.getContentText()).access_token;
}
function idealoDownloadDailyClickReport(shopId,siteId,fromDate,toDate,access_token){
const url = "https://businessapi.idealo.com/api/v1/shops/"+shopId+"/daily-click-reports/download?site="+siteId+"&from="+fromDate+"&to="+toDate;
const response = UrlFetchApp.fetch(url, {
"method": "GET",
"headers": {
"Authorization": "Bearer "+access_token,
"Content-Type": "application/json",
},
"muteHttpExceptions": true,
"followRedirects": true,
"validateHttpsCertificates": true,
"contentType": "application/json",
});
return Utilities.parseCsv(response);
}Workaround für FTP-Empfang
Um via FTP empfangene CSV-Daten auf die gleiche Weise verarbeiten zu können, schicken wir sie uns mittels BASH-Script als Anhang per E-Mail an unser Reporting-Postfach.
#!/bin/bash
inotifywait -m -r /var/www/********/htdocs/******** -e create -e moved_to |
while read dir action file; do
sleep 10
subdir="main"
needle="\/(.[^\/]*)\/$"
if [[ $dir =~ $needle ]]
then
subdir="${BASH_REMATCH[1]}"
fi
echo "The file '$file' appeared in sub-directory '$subdir' via '$action'"
echo "Datei '$file' von '$subdir' via FTP empfangen ." | mutt -x -s "******** $subdir reportings" -a $dir$file -- ********@adtraffic.de
today=$(date +"%Y%m%d")
mkdir /var/www/********/htdocs/********/$subdir
mkdir /var/www/********/htdocs/********/$subdir/$today
mv -f $dir$file /var/www/********/htdocs/********/$subdir/$today/$file







